
Winning Work with AI
- Mar 30
- 5 min read

Tender documents are complex. A typical invitation to tender arrives as a set of PDFs, spreadsheets, and appendices that together can run to hundreds of pages. You need to understand the requirements, cross-reference them against evaluation criteria, pull in evidence from your own past work, check compliance obligations, identify risks, and produce a coherent response that is scored against specific weightings by evaluators who have seen dozens of similar submissions. It is a process that demands research, synthesis, and precision, which makes it a natural fit for AI. But, and this is an important but, it is a terrible fit for a chatbot.
The reason is context. Most AI chatbots let you upload a handful of documents, perhaps ten or twenty, and ask questions about them. That is fine for simple tasks. But a serious tender response draws on far more than the tender documents themselves. You need your company's past proposals, capability statements, case studies, staff CVs, client testimonials, research data, and organisational policies. By the time you have gathered everything relevant, you are looking at hundreds of documents, and a chatbot's context window simply cannot hold all of that at once.
The alternative is a RAG system: Retrieval Augmented Generation. The concept is straightforward. Instead of feeding everything into a single conversation, you build a searchable knowledge base from all of your documents. When you ask a question, the system finds the most relevant passages from across that entire collection and presents them to the AI, which then generates its answer grounded in your actual evidence rather than its general training data. The AI answers from your documents, not from the internet. [1]
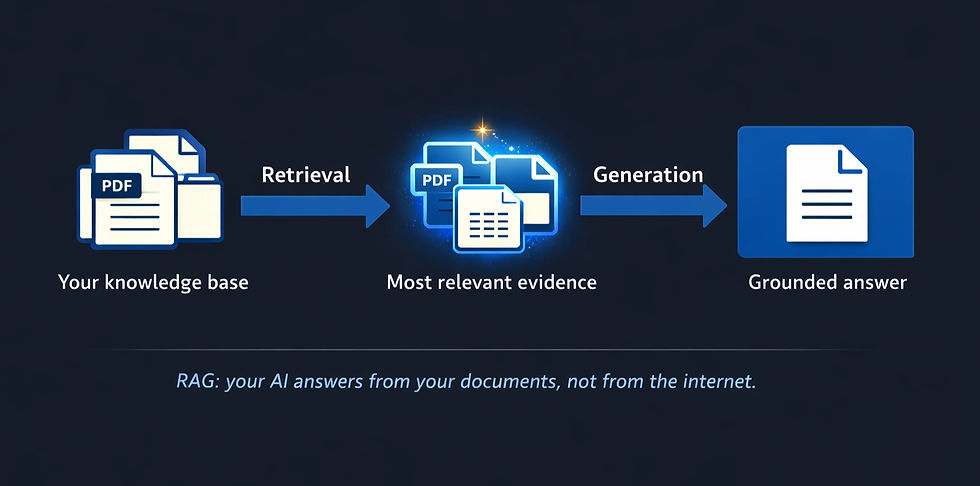
We built exactly this for ChangeSchool's tender work. The system currently holds over 250 tender document sections and more than half a million passages from our organisational capability library, all searchable using a combination of keyword and semantic search with re-ranking to surface the most relevant results.
In practical terms, this means I can ask the system to analyse a new tender's evaluation criteria and it will extract dates, requirements, compliance obligations, and scoring weightings. I can ask it to generate a proposal outline, and it will produce a structured response with section headings, page allocations, and notes on what evidence to include. I can ask it what the evaluators are really looking for in a particular question, and it will interpret the evaluation intent and suggest where to focus for maximum scores. I can ask it to identify risks in the contract terms, and it will come back with severity ratings and suggested mitigations.
The red-teaming capability is where it gets particularly useful. Before submitting a proposal, you can ask the system to evaluate your draft response from the perspective of a sceptical evaluator. Where are the weaknesses? What claims are unsupported? Where might a competitor have a stronger story? That kind of adversarial review is something most small and medium-sized companies simply do not have the resources to do well internally, and it makes a material difference to submission quality.

All of this runs on consumer hardware. The knowledge base sits on a local machine, not in the cloud. There is no subscription cost beyond the AI model's API fees, which for a full tender analysis run to a few pounds. The documents never leave your control unless you choose to send specific queries to the AI provider for generation, and even then the provider's commercial terms prohibit training on your data. [2]
There is a broader point here about the shift from chatbot to system. A chatbot is a conversation. A RAG system is an infrastructure. Once you have built it, it is there for every tender, every proposal, every piece of research your team needs to do. Each new document you add makes the whole system more capable. It accumulates institutional knowledge in a way that a chatbot, which starts fresh every conversation, never can.
The discipline from earlier in this series applies. The business need was clear: we were spending too long on tender research and not producing consistently strong responses. The outcome we defined was a system that could analyse any new tender against our full body of evidence and produce structured, grounded outputs. The plan was to build a local RAG system using open-source embedding models and a commercial AI for generation. We delegated the retrieval and analysis to the system, and we review every output before it goes anywhere near a submission. The human writes the final proposal. The AI ensures it is built on the strongest possible foundation.
Sources
[1] RAG (Retrieval Augmented Generation): a standard AI architecture where a retrieval system finds relevant document passages and presents them to a generative model. See: Lewis, P. et al. (2020), Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS 2020.
[2] Revised. Anthropic commercial API terms: user inputs and outputs are not used to train models. Anthropic retains inputs for a limited period for safety review purposes only. See Anthropic's usage policy for current terms at anthropic.com/legal/privacy.
About the series
This article is part of a series on practical AI applications at ChangeSchool. For the strategic view of leading AI in organisations, see Viren Lall's companion series. ChangeSchool is an SME without a dedicated coding resource. Every application described in this series was built using AI coding tools. They are all vibe coding projects, and all within the reach of a startup or a micro business willing to spend some hours and have a go. If you've got any questions about what this was or how we did it, or any suggestions for better ways forward, please pop them in the comments below and I'll do my best to answer them.
Technical Note
Our process is the same for every project. Once the business need and objective are defined, we research the approach using Google Gemini Deep Research and Perplexity Deep Research, then give that research to Claude Code to build it. None of the technical terms below were things we knew beforehand; they came out of that research process. It takes minutes to get up to speed. Built in Python using Claude Code. The knowledge base uses ChromaDB (trychroma.com) as a local vector database, with the open-source Nomic Embed Text v2 MoE model for embeddings (huggingface.co/nomic-ai/nomic-embed-text-v2-moe) and a cross-encoder re-ranker for result quality (huggingface.co/cross-encoder/ms-m arco-MiniLM-L-6-v2). Document parsing uses Docling. Generation uses the Anthropic Claude API. All embedding and re-ranking models run locally on consumer hardware and can be downloaded free from Hugging Face.


